Planes of a Human Face Used to Draw Caricatures
ane Introduction
Caricatures have been used for centuries to convey sense of humour or sarcasm. References can be found during the Antiquity with Aristotle referring to these artists as "grotesque," or in the works of Leonardo Da Vinci who was eagerly looking for people with deformities to use every bit models. Caricature can be defined as the art of drawing persons (ordinarily faces) in a simplified or exaggerated way through sketching, pencil strokes, or other artistic drawings. Caricatures have been ordinarily used to entertain people, to laugh at politics or every bit a gift or gift sketched past street artists. These artists have the power to capture distinct facial features, and and then exaggerate those features (Redman, 1984). With the evolution of social VR networks or games, users may wish to use stylized avatars, including avatars preserving their identity (Olivier et al., 2020) merely with such exaggerated features. Hence, automatically generating such caricatured avatars becomes a key upshot, every bit having artists manually creating caricatured avatars would not be feasible for such applications involving large numbers of users. Let united states consider a 3D mesh representing the user'southward face (either using 3D scanning or reckoner vision methods to build 3D shape from a minimum set of images). An automatic extravaganza organization should maintain the relative geometric location of facial components, while emphasizing the subject area's facial features distinct from others. While different caricature experts would generate different styles of faces (more than or less cartoonish mode for case), they would all be exaggerating facial traits of the individual (Brennan, 1985; Liang et al., 2002; Mo et al., 2004). The ability of creating a variety of plausible caricatures for each unmarried face is therefore a cardinal challenge when automatically generating caricatures, as different artists would create visually different caricatures, which should also exist taken into account when evaluating the subjective quality of the results.
Previous works for the generation of 3D caricatures tin be separated into two primary families: interactive and automatic methods. Interactive methods offer tools to extravaganza experts to design the resulting caricature (Akleman, 1997; Akleman et al., 2000; Chen et al., 2002; Gooch et al., 2004), while fully automatic methods utilise hand-crafted rules (Brennan, 1985; Liang et al., 2002; Mo et al., 2004), oftentimes derived from the drawing procedure of artists. However, these approaches are typically restricted to a particular artistic style, eastward.k., sketch or a certain cartoon, and predefined templates of exaggeration. From the works in the literature in other domains, two different solutions could exist envisioned to automatically generate caricatures. Start, in the context of exaggerating distinct features, Sela et al. (2015) proposed a generic method to exaggerate the differences between the 3D scan of an object and an boilerplate template model of such type of object. Nevertheless, this method has never been formally evaluated for human faces. Second, deep learning methods could be considered. As mentioned above, automatic methods mainly use mitt-crafted rules that may fail to capture some complex choices made past caricature experts. In contrast, generative adversarial networks (GANs) are a promising mean to effort to larn these choices based on a set of examples made by experts, without being express to hand-crafted rules, just it has been never applied for the generation of 3D caricatures. The main goal of this newspaper is to advise and evaluate novel methods for the automatic generation of 3D caricatures from real 3D facial scans, kickoff with a dominion-based method, in order to keep tunable and interpretable parameters, and a deep learning method, to leverage existent caricature data and hence generate caricatures closer to existent ones. The main hypotheses we wish to address in this newspaper are:
H1: the specialization of generic exaggeration methods for human faces should permit to produce convincing caricatures. To this end, we adapted the generic method proposed by Sela et al. (2015) in society to generate caricatures by exaggerating facial features from a 3D face browse (see Figure i). This method has two principal stages, one based on a curvature EDFM (Exaggerating the Difference From the Mean), and another based on a nearest-neighbors search in a 3D extravaganza dataset, to apply the proportion exaggeration.

Effigy 1. Results of our novel user-controlled dominion-based approach. Each pair (A, B, C, and D) presents the input facial scan (wired on the left) and its automatically generated caricature on the correct.
H2: deep learning should permit to overcome some of the limitations of rule-based methods by their ability to generalize based on a ready of examples. Thus, we designed a method leveraging advances in the field of GAN-based way transfer, which has shown great success in the 2D domain, for example on drawn caricatures (Cao et al., 2019).
H3: both methods should reach and overcome the country-of-the-art results when trying to automatically generate caricatures from a homo confront 3D scan. To assess the advantages and disadvantages of the proposed methods, we conducted a perceptual study considering the base method proposed past Sela et al. (2015) and an boosted EDFM method (Akleman and Reisch, 2004).
The results of the study support hypotheses H1 and H2, as the perceptual written report demonstrated no significant preference of the subjects for any of the tested methods, for the proposed human being faces. Although this result shows that the ii proposed methods reached land of the art functioning (H3), the perceptual study did not show a clear winner, highlighting the difficulty to simulate and evaluate such artistic caricatures for which a big diversity of styles and solutions exists. The balance of the newspaper is structured as follows. First, Section 2 reviews the land of the fine art, and identifies the gaps between existing techniques. Section 3 and Department 4 nowadays the proposed dominion-based and deep learning-based caricaturization methods respectively. Then, Section 5 presents the perceptual evaluation of the proposed methods with land-of-the-art methods. Finally, we talk over the results and provide insights on the automatic caricature generation in Section vi.
2 Related Work
Computer assisted extravaganza generation has been a topic of involvement for researchers since the start of Reckoner Graphics (Brennan, 1985). Typically, techniques from cartoon guides, such as Redman's practical guide 1984) on how to draw caricatures, are exploited. This guide sets the primal rules of caricatures and proposes some concepts that are massively used. Among them, the "mean face assumption" implies the being of an average face, and the process of "Exaggerating the Difference From the Mean" (EDFM) consists in emphasizing the features that make a person unique, i.e., unlike from the average face. Existing methods for automatic extravaganza generation split into two principal categories: dominion-based and learning-based methods.
2.1 Dominion-Based Methods
Rule-based methods utilize a priori known procedures to caricaturize a shape. They tin exist further divided into ii branches depending if their domain of application is on man faces or other shapes.
Face dominion-based methods follow caricature cartoon guidelines (eastward.g., EDFM) to generate plain-featured faces with emphasized features. Brennan (1985) first proposed an implementation of EDFM in two dimensions. They built an interactive system where a user tin can select facial feature points which are matched against the average feature points, then the distance between them is exaggerated. This algorithm was later extended past Akleman et al. in 2d and 3D domains (Akleman, 1997; Akleman and Reisch, 2004). Their software relies on a low-level procedure which requires the user to decide whether the exaggeration of a characteristic increases likeness or not. In the same spirit, Fujiwara et al. (2002) adult a piece of software named PICASSO for automatic 3D caricature generation. They used a gear up of feature points to generate simplified 3D faces before performing EDFM. EDFM was also used by Blanz and Vetter (1999) in an application example of their morphable model. They learn a principal component analysis (PCA) infinite from 200 3D textured faces. Their system allows caricature generation by increasing the altitude to the statistical hateful in terms of geometry and texture. Statistical dispersion has been taken into account by Mo et al. (2004) who showed that features should be emphasized proportionally to their standard departure to preserve likeness. Chen et al. (2006) created 3D caricatures by fusing 2D caricatures generated using EDFM from different views. Redman's guide (Redman, 1984) not only introduces EDFM but also high levels concepts such every bit the five caput types (oval, triangular, squared, circular and long) and the dissociation between local and global exaggeration. These concepts have been exploited by Liu et al. (2012) to perform photograph to 3D extravaganza translation. They applied EDFM with respect to the shape of the caput (global scale) and to the distance ratios of a prepare of feature points (local scale). Face rule-based methods can generate a caricature from an input photograph or a 3D model just fail at reproducing artistic styles. Different caricaturists would make different caricatures from the same person. To avoid this issue, they unremarkably provide user control at a relatively low-level of comprehension, which often requires artistic knowledge.
Not face specific rule-based methods rely on intrinsic or extracted features of geometrical shapes. They generalize the concept of extravaganza beyond the domain of human faces. Eigensatz et al. (2008) developed a 3D shape editing technique based on principal curvatures manipulation. With no reference model, their method can heighten or reduce the sharpness of a 3D shape. The link between saliency and caricature has been explored by Cimen et al. (2012). They introduced a perceptual method for caricaturing 3D shapes based on their saliency using free class deformation technique. A computational approach for surface caricaturization has been presented by Sela et al. (2015). They locally calibration the gradient field of a mesh past its accented Gaussian curvature. A reference mesh tin can be provided to follow the EDFM rule, and the authors show that their method is invariant to isometries, i.e., invariant to poses. General shape rule-based methods tin besides caricature a 2nd or 3D shape without whatever reference model. As they do not take into account whatever statistical information nor the concept of creative style, they try to link low-level geometry information to high-level extravaganza concepts, e.k., the fact that the most salient expanse should be more exaggerated (Cimen et al., 2012). As a issue, they do not take into account the semantic of faces nor the art of human face caricature.
Since this work only tackles human face up caricaturization, we refer to "face up rule-based methods" as simply "rule-based methods".
2.two Learning Based Methods
Existing learning-based methods for caricature generation can use both paired and unpaired information as training material.
Supervised data-driven methods would automatically discover rules by relying on pairs of exemplars to learn a mapping between the domain of normal faces and the domain of caricatures. Xie et al. (2009) proposed a framework that learns a PCA model over 3D caricatures and a Locally Linear Embedding (LLE) model over 2d caricatures, both made past artists. The user can manually create a deformation that is projected into the PCA subspace and refined using the LLE model. Li et al. (2008) and Liu et al. (2009) both focused on learning a mapping between the LLE representation of photographs and their respective LLE representation of 3D caricatures modeled by artists. In the same vein, only only in the 3D domain, Zhou et al. (2016) regressed a set of locally linear mappings from sparse exemplars of 3D faces and their corresponding 3D caricature. As far as we know, Clarke et al. (2011) are the simply authors that proposed a physics-oriented caricature method. They capture the artistic manner of 2D caricatures past learning a pseudo stress-strain model which describes physical properties of virtual materials. All these data-driven approaches are based on paired datasets which crave the piece of work of 2D or 3D artists. Such datasets are plush to produce, therefore techniques of this kind are hardly applicable.
Unsupervised learning based methods learn how to caricature from unpaired face and extravaganza exemplars. Chen et al. (2001) and Liang et al. (2002) generated 2D caricatures past learning a nonlinear mapping betwixt photos and respective caricatures made by artists. Derived from the prototype synthesis literature, where they take been used for unpaired one-to-i translation (Liu et al., 2017; Taigman et al., 2017; Yi et al., 2017; Zhu et al., 2017), or unpaired many-to-many translation (Huang et al., 2018b; Liu et al., 2019; Choi et al., 2020), Generative Adversarial Networks (GANs) have also shown impressive results on mesh synthesis and mesh-to-mesh translation (Goodfellow et al., 2014). Other approaches reach 2D stylization using 3D priors and a differentiable renderer (Wang et al. (2021).) Cao et al. (2019) proposed a photograph to 2D caricature translation framework CariGANs based on a large dataset of over half-dozen,000 labeled 2D caricatures (Huo et al., 2018), and 2 GANs, namely CariGeoGAN for geometry exaggeration using landmark warping, and CariStyGAN for stylization. CariStyGAN allows to use a reference graphic fashion, or else, it will generate a random style. This framework was first extended by Shi et al. (2019) with a feature point-based warping for geometric exaggeration, and then by Gu et al. (2021) which provides a random fix of deformation styles in addition to the random set of graphics styles, offering consistent user control. In the 3D domain, Wu et al. (2018) then Cai et al. (2021) proposed robust methods for 3D caricature reconstruction from meshes, enlarging the set of available in-the-wild 3D caricatures, when used in combination with WebCaricature (Huo et al., 2018). Guo et al. (2019) showed an arroyo for producing expressive 3D caricatures from photos using a VAE-CycleGAN. Ye et al. (2020) proposed an end-to-stop 3D caricature generation from photos method, using a GAN-based architecture with two symmetrical generators and discriminators. A footstep of texture stylization is performed with CariStyGAN. The recent works for caricature generation in 3D domain permit to reproduce the style of artists but they do non feature much user control. Ye et al. (2020) introduced Facial Shape Vectors so the user tin cull the facial proportions on the caricature, only this is a quite depression-level interaction and thus should be washed by an artist. These works as well evidence a weakness from the use of CariStyGAN for texture stylization. CariStyGAN tends to emphasize the shadows and light spots of the photos in order to make the reliefs sharper. In the instance of textured 3D models, the shadows and low-cal spots should be induced by the geometry and the lighting conditions, not past the texture albedo. If lighting information is entangled inside texture information, changing the lighting condition can make the 3D model appear to exist enlightened by non-existent lights.
Adopting a 3D mesh representation requires application of mesh convolutions defined on non-Euclidean domains (i.east., geometric deep learning methodologies). Over the past few years, the field of geometric deep learning has received significant attention (Litany et al., 2017; Maron et al., 2017). Methods relevant to this paper are auto-encoder structures such as used past Ranjan et al. (2017) and Gong et al. (2019), that showcase the efficiency of recent 3D convolutional operators at capturing the distribution of 3D facial meshes. Several approaches resort to mapping 3D faces to a 2D domain, and using second convolution operators (Moschoglou et al., 2020). Projecting a 3D surface to a 2d aeroplane for 2D convolutions requires locally deforming distances, which translates to higher computing and memory costs compared to recent 3D convolution approaches, and some high-frequency data loss (Gong et al., 2019).
Deep learning based approaches, leveraging recent advancements in the field, could produce caricatures more similar to the kind produced past professionals, and let global manner control using handmade caricatures as style examples. On the contrary side, a user-controlled rule-based approach enabling a local control of the facial mesh deformation would allow for fine-tuned local control. We develop both approaches in Section three and Section iv. Finally, there is no overall perception user study of this specific field, limiting whatsoever qualitative comparison between approaches. We present the first study of this kind in Section five, in order to evaluate the strengths and drawbacks of these ii novel methods in comparing to two state-of-the-art approaches.
3 Rule-Based User-Controlled Caricaturization
We present a novel method featuring brusk computation time and providing meaningful user command over the generated caricatures. Information technology is based on two main modules depicted in Figure 2 (in green and in yellow). Start, a curvature exaggeration module (in green) enhances the facial lines by applying EDFM technique to the main PCA scores of the mesh gradients of the input face up. This emphasizes only the 3D surface details such as ridges, peaks, and folds, and does non affect the global shape of the confront (such as eyes, nose, and mouth relative positions). Second, a proportion exaggeration module (in xanthous) leverages compositions of real artists (see Section 3.i) to extravaganza the general shape of the face up. It projects the input confront into a 3D extravaganza shape space thanks to a kNN regressor. This process applies a smooth and large scale deformation to the input face while preserving its local features. The curvature exaggeration and proportion exaggeration modules are thus complementary. They are combined to provide the user with a bilateral command (small scale versus large scale) over the resulting caricature. Lastly, an optional texture blurring and contrast enhancement module (in pink) makes the resulting caricature less realistic and more graphic. The reason behind this step is to make the upshot more adequate for homo observers. As shown by Zell et al. (2015), nosotros use texture blurring because it increases the appeal and lowers the eeriness of a virtual graphic symbol. The increment in dissimilarity is meant to brand the caricatures less realistic, but one could have used another technique to this finish. In addition to these modules, our user-controlled method features semantic mesh division in 4 regions (see Department 3.ii). In total, the method exposes ten knobs to the user.

FIGURE two. Overview of our user-controlled method presented in Section iii. Arrows and diamond shapes represent algorithms while boxes represent data. Offline and online processing are represented past the blueish and orange colors, respectively. Green, yellow, and pink highlights show the different modules which compose the core of the user-controlled caricature system. For simplification purposes, the face segmentation is non shown.
3.1 Datasets
Realistic 3D faces were sampled from the LSFM dataset (Berth et al., 2016) which contains near 10k distinct 3D faces. In society to have textured meshes, we completed this set with 300 in-house 3D face scans. Their topologies are unified through automatic facial landmarking and geometry plumbing equipment (Danieau et al., 2019). To build our 3D caricatured mesh dataset, we run the 2d to 3D extravaganza inference method of Cai et al. (2021) on the WebCaricature dataset (Huo et al., 2018), which enables to excerpt the 3D caricatured face mesh from each 2d epitome. The WebCaricature dataset contains over 6k second caricatures. When Cai's algorithm did not successfully estimate the faces, due to extreme drawing composition (quick sketch, incomplete drawings, drafts, cubism etc.) the generated output remains the aforementioned default extravaganza mesh. All faces were then registered, in gild to have a fixed topology (Sumner and Popović, 2004).
three.2 Facial Segmentation
In face modeling, cartoonization and caricaturing, semantic segmentation is a popular technique for increasing expressivity and user interaction (Blanz and Vetter, 1999; Liu et al., 2009; Zhou et al., 2016). In the proposed system, the 3D faces are segmented using the scheme proposed by Blanz and Vetter (1999) i.e. in four regions: the eyes, the nose, the oral cavity, and the rest of the confront. This semantic segmentation allows the user to choose whether to emphasize or not a facial part. In total, the method exposes ten knobs to the user: one scalar is used for the strength of the gradient EDFM and some other one for the amount of deformation from the kNN regressor to be added. Those two weights are tunable for each of the v regions (four masks and full face). Segmenting the domain besides allows to break the inherent linearity of PCA by learning different subspaces.
three.three Curvature Exaggeration
To emphasize the pocket-size scale features of the input 3D face, the curvature exaggeration module performs EDFM on the mesh gradient. In the process, we use PCA every bit a mean to reduce loftier frequencies (Effigy 3).
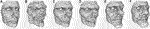
FIGURE three. Different curvature exaggeration techniques: (A) Original 3D Mesh. (B) Naive gradient EDFM without partitioning (f grad = 5). (C) Slope EDFM with PCA denoising, without partitioning and (D) with segmentation (f grad = 5). (E) Sela et al. (2015)'s method, without reference model (γ = 0.3) and (F) with the hateful face equally reference model (β = 4). More examples in Supplementary Textile, at Supplementary Figure 23.
• Offline preprocessing. The border-based gradient operator E (see Supplementary Material) is used to compute the gradients g of each face mesh s of our custom 3D face dataset (Section 3.i). Post-obit the results of Mo et al. (2004) showing that low-variance features should be more taken into account, the gradients Grand are standardized:
• Runtime curvature exaggeration. The input confront mesh due south is standardized so projected into the PCA space learnt offline. EDFM technique is applied with a factor f grad given by the user. To prevent racket, we weight the result past the normalized standard deviation associated to each principal component
3.4 Proportion Exaggeration
The proportion exaggeration module leverages the 3D caricatures (see Department 3.1) to sample a deformation that matches the input confront difference from the mean using a kNN. Thus, it can be seen as an instance-based version of EDFM. We contend that the sampled deformation contains mainly low frequencies and adding it to an input face will modify very little its surface curvatures. We observed that the 3D caricatures have more diverse global shapes than our 3D faces while existence much smoother. In addition, the one thousandNN regression also contributes to shine out the deformation by averaging the yard nearest neighbors. The process works as follows:
• Offline preprocessing. The 3D caricatures are outset standardized using the standard difference of our 3D faces to make the low-variance areas more important (Mo et al., 2004). And so, we fit a kNN regressor using a cosine distance metric, equally we mainly seek to observe directions of deformation rather than amplitudes of deformation. The amplitude tuning is reserved for the user.
• Runtime proportion exaggeration. The input confront is standardized so projected into the 3D caricature space with the thouNN regressor using barycentric weights. The obtained deformation δ std is weighted past the 3D face standard difference σ S and by a user-defined scalar f prop for amplitude tuning. Eventually, we add this deformation to the curvature exaggerated face up to get the vertex positions of the resulting caricature c:
3.5 Results
In this section, the results of both the curvature exaggeration module and the proportion exaggeration module are presented and compared to those of their most like existing approaches. We compare the curvature exaggeration module to Sela et al. (2015) considering they ready the positions of border vertices and therefore tend to preserve the proportions of the caricatured faces. Our proportion exaggeration module is compared to the baseline 3D position EDFM introduced in the seminal work of Blanz and Vetter (1999).
• Curvature exaggeration module. The benefit of the PCA-based denoising mechanism is visible in Figure 3 betwixt column b), and cavalcade c) and d). Without PCA, the EDFM technique magnifies the existing high frequencies of the face's difference from the mean. With PCA, the noise is removed just the exaggeration of facial lines remains. The use of a segmented model not merely enables to provide more user-control, but also to emphasize the curvatures more locally. This effect tin be noticed when comparing the results c) and d) in Figure 3. Sela et al. (2015)'s method successfully preserves the position of the eyes, the nostrils, the inner lips and the contour of the face. However other parts such as the olfactory organ, the lips and the chin seem profoundly inflated and displaced which should not belong to facial lines enhancement. Conversely, our curvature exaggeration module modifies the vertex positions such that it merely enhances the fine curvature details.
• Proportion exaggeration module. Figure 4 shows the effect of modifying one thousand on the results of our proportion exaggeration module. Visually, the parameter k of the kNN regressor has less bear on than nosotros expected. Notwithstanding, it appears that a small value of grand (

Effigy four. A comparison of results with different values of thou for the mNN algorithm of the proportion exaggeration module. The first column shows the original facial mesh. Hither, the caricatures are generated with f proportions = two.
The semantic sectionalization has also an impact on our proportion exaggeration module. In Figure 5, the results with sectionalisation (cavalcade c) seem more caricatural only also more expressive than without segmentation (column b). Expressiveness is not intended by the proposed method since the focus is on neutral expression caricature generation. Nonetheless, we decided to conserve the sectionalisation scheme for the proportion exaggeration module. We also compare the proportion exaggeration algorithm to the baseline PCA-based EDFM on 3D coordinates proposed by Blanz and Vetter (1999) (cavalcade d). Our method clearly generates more diverse and inhomogeneous shapes than Blanz and Vetter (1999)'s approach. It is also noticeable that less loftier-frequency details are added than with the baseline method, which is what we aim at.
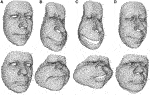
FIGURE 5. A comparison between proportion exaggeration techniques on 2 facial meshes. (A) Original facial mesh. (B) Our proportion exaggeration algorithm without partitioning and (C) with division. (D) Baseline PCA-based 3D positions EDFM (Blanz and Vetter, 1999).
4 Deep Learning Based Automatic Caricaturization
Dominion-based methods let the use of controllable and interpretable parameters, but are limited to capture data about caricature styles. Supervised learning based methods require a large paired mesh-to-caricature dataset, that are highly consuming in terms of both time and means to build. Instead, nosotros consider the instance of an unpaired learning-based approach, taking reward of our 3D datasets of both neutral and caricatured faces (Cai et al., 2021) (cf. Section 3.1). Our network architecture is based on the shared content space assumption of Liu et al. (2019), that we adapt to the context of 3D data through the use of 3D convolutions of Gong et al. (2019), which ascertain 3D convolution neighborhoods.
4.1 Framework Overview
Let us consider meshes of different styles (e.one thousand. scans and caricatures), all sharing the same mesh topology. We represents our faces with raw 3D coordinates, and encode them using a recent 3D convolutional operator (Gong et al., 2019). Given a mesh ten ∈ X and an arbitrary manner y ∈ Y, our goal is to railroad train a single generator G that can generate diverse meshes of each style y that corresponds to the mesh ten. Nosotros generate mode-specific vectors in the learned infinite of each style and train G to reverberate these vectors. Figure 6 illustrates an overview of our framework, which consists of three modules described beneath.
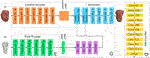
FIGURE 6. Overview of UNGT. A facial scan'due south identity is encoded along with the mode of a extravaganza mesh, in order to produce the caricatured face up. Textures are not processed, and presented for illustration purpose only. E represent the Style Encoder, One thousand the Generator, and D the Discriminator.
Generator. Our generator G translates an input mesh ten into an output mesh Yard (10, s) reflecting a way-specific style code s, which is provided by the style encoder Eastward. Nosotros use adaptive instance normalization (AdaIN) (Huang and Belongie, 2018a) to inject south into Grand. We detect that s can represent any style, which removes the necessity of providing y to One thousand and allows Chiliad to synthesize meshes of all domains.
Style encoder. Given a mesh x, our encoder E extracts the style codes s = E(x). Similar to Liu et al. (2019), our manner encoder benefits from the multi-task learning setup. E can produce various style codes using different reference meshes. This allows G to synthesize an output mesh reflecting the style code southward of a reference mesh x.
Discriminator. Our discriminator D is a multitask discriminator (Mescheder et al., 2018; Liu et al., 2019; Choi et al., 2020), which consists of multiple output branches. Each branch D y learns a binary classification determining whether a mesh x is a mesh from the dataset of style y or a fake mesh G (x, south) produced by G.
4.two Grooming Objectives
Given a mesh x ∈ X and its original style y ∈ Y, we train our framework using the post-obit objectives:
• Adversarial objective. During training, nosotros sample a mesh a and generate its style lawmaking s = E(a). The generator G takes a mesh x and s equally inputs and learns to generate an output mesh G (ten, s) that is indistinguishable from real meshes of the style y, via a classical adversarial loss (Arjovsky et al., 2017):
where D y (⋅) denotes the output of D respective to the style y.
• Reconstruction and cycle losses. To guarantee that the generated mesh G (10, s) properly preserves the style-invariant characteristics (e.g. identity) of its input mesh x, nosotros employ the bike consistency loss (Kim et al., 2017; Zhu et al., 2017; Choi et al., 2018)
where
where
• Full objective. Our objective office can exist summarized equally follows:
where λ r and λ cyc are hyper parameters for each term. We use the Adam Optimizer (Kingma and Ba, 2015).
4.iii Results
Nosotros trained the network for 50k iterations on a Titan X Pascal (4h, 8Go). Results of the approach are visible in Effigy 7. The original faces (top row) are encoded using the network illustrated in Figure 6 forth with a random extravaganza of the dataset, producing the caricatured face up (lesser row). Facial proportions are hence exaggerated according to the distribution of the neutral and caricatured faces learned during the training stage.
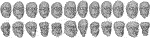
Effigy 7. Deep learning based caricatures for a number of facial scan examples.

FIGURE eight. The v best caricatures (with the best mean ranks; identities 7, half-dozen, 9, 12, 2).
5 User Written report
In guild to assess the subjective quality of the caricatures generated by the previously described methods, we have conducted a perceptual study. The goal of the perceptual report was to subjectively rank the generated caricatures based on the perceived quality of the caricatures. In addition to the 2 methods described in Section 3 and Section iv, we also considered two baseline methods, the method from Sela et al. (2015) and a EDFM method (Blanz and Vetter (1999)).
five.ane Participants
Twoscore-9 participants took part in the experiment (9 females). They were between 18 and 63 years old (mean and STD historic period: 31.0 ± xi.3), and were recruited from our laboratory among students and staff. They were all naive to the purpose of the experiment, had normal or correct-to-normal vision, and gave written and informed consent. The report conformed to the declaration of Helsinki. Participants were non compensated for their participation and none of the participants knew the human being faces used in the study.
5.2 Stimuli
The elevation part of Figure 7 presents the 12 human face up scans (Identity cistron) used in the study (four females, viii males). They were caricatured using five different approaches (Method factor): the learning-based approach (Deep) presented in Section 4, two variations of the rule-based arroyo presented in Department 3 (see Tabular array i), and ii state-of-the-fine art caricaturization methods–EDFM (Blanz and Vetter, 1999) and Sela (Sela et al., 2015). For each confront (original and caricatured), we used the cartoonization module presented in Section 3. The texture blurring is expected to reduce the mismatch of realism betwixt the shape and the texture and therefore brand the caricature more acceptable to human observers (Zell et al., 2015). The stimuli were rendered with a rotation of thirty°around the vertical axis, with a fixed view. The bending was called as a common viewpoint between a frontal and profile view. We considered merely the facial mask, hence other facial attributes such as eyes and hair were not displayed.

Tabular array 1. Parameters sets of the 2 variations of our rule-based method used in the user study (Section 5). The beginning variation targets the proportions more than while the 2d strongly exaggerates the curvatures. These parameter sets aim at exploring the range of user control provided to the user. A number of other variations could have been proposed, but nosotros meet complexity restrictions for the user written report.
v.iii Protocol
The perceptual report consisted of 2 parts. The outset part of the written report assessed the results produced by each method for each face, co-ordinate to participant'due south preferences. For each human facial scan, participants were presented with the original face and the caricatures generated with the five methods. They were asked to rank all five caricatures from the best to the worst extravaganza. The lodge of the scans and the presentation of the caricatures was randomized independently for each participant and each facial browse was only presented once, for a total of 12 trials. The second part of the study aimed at evaluating globally each of the five methods. For each method (in a random society), the caricaturization results (12 facial scans) were displayed at once. Participants were asked to indicate how much they agreed to three statements using 5-point Likert scales. The statements were "They preserve the identity of the person," "They correspond to what would be expected of a extravaganza," "I similar the results". In that location was no time limit for whatsoever of the two parts, and the evaluation was conducted online using the PsyToolkit software (Stoet, 2010, 2017). Nosotros include a sample view of the ranking chore in Supplementary Figure 22. A render of all 12 caricatures for each method tin exist seen on Supplementary Figures 17–19, 21.
five.4 Results
We present in this section the statistical results of the user study.
5.iv.1 Average Rankings
To clarify ranking distributions (Figures 9–Figure 10), nosotros first performed a Friedman examination with the within-subject cistron Method (using the average rank between all 12 scans). We found an effect of the Method on average ranking (χ ii = 12.21; p < 0.05). The outcome is and so explored farther using a Wilcoxon post-hoc test for pair-wise comparisons. We establish significant differences simply betwixt EDFM and Deep, Geo.ane, Sela (all p < 0.05). Nosotros institute that per method, average rankings vary between 2.81 (EDFM) and iii.12 (Deep) x. In order to determine whether ranking distributions per method differed with identities, nosotros used a Friedman test with within-subject factors Method and Identity. Out of 12 distinct identities, vi (identities two, 5, half-dozen, 7, 11, 12) showed significantly dissimilar rankings between methods. This is in most cases (5 out of vi) due to worse than average functioning from a set of methods, usually Deep or Sela.
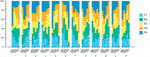
Effigy 9. Average rankings, per Method and Identity. R1 to R5 are the ranks 1 to rank five. Notation the high variance per face and method.
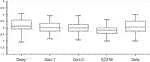
FIGURE 10. Boxplot of the average rankings over participants, per method. Rankings range from 1 to five. Overall, all methods achieve similar performances, averages beingness between 2.81 and 3.12 (lower is better).
5.4.2 Top Rankings
Nosotros measured Summit-1, Top-two, and Top-3 rank differences per method, using Friedman tests, Height-X rankings being the number of times the techniques were ranked Ten or lower (lower is improve, Figure 11). We institute no significant differences for Top-1 (χ ii = iv.xiv; p = 0.38) rankings, merely an event was institute for both Top-2 (χ 2 = 9.74; p < 0.05) and Top-3 rankings (χ two = 34.lx; p < 0.001). The effect for Acme-2 and Top-iii rankings is then explored using a Wilcoxon mail-hoc exam. For Acme-2 rankings, we found that EDFM was chosen significantly more than often as first or second choice than Deep (p < 0.05) and Sela (p < 0.01). For Tiptop-3 rankings, we found a similar preference for EDFM over Deep, Geo.1, and Sela (p < 0.05), as well every bit a significant lower preference for Sela over all others (p < 0.05).

FIGURE eleven. Caricature ranking distribution across all participants, per method. Tiptop-ane to Top-5 rankings respectively shown in light blue, light-green, yellow, orangish, and blue.
v.iv.3 Variations Between Participants
We looked into participant-wise preferences for caricature methods using a Friedman test on ranking choices of each participant, individually. Out of 49 participants, separate Friedman tests on their Top-1 rankings showed that but 12 had a meaning preference towards a fix of methods, and out of these only 4 towards a specific one. These numbers are as well low to prove anything conclusive in that regard.
5.4.4 Subjective Scores
Subjective ratings results were analyzed separately using a one-way ANOVA with within-subject area factor Method on the information of each question. All subjective results differences between methods were found to be significant (p values of 5.7e − six, 7.35east − 6, and 2.28e − 5). We conducted carve up post-hoc analyses using Wilcoxon. For the statement "They preserve the identity of the person" (Figure 12), significantly different groups of method were Deep, Sela (mean = 3), and Geo.ane, EDFM (hateful = 2.3). The method Geo.2 (mean = 2.half-dozen) was non significantly different from others. For the statements "They correspond to what would be expected of a caricature" (Figure 13) and "I like the results" (Figure 14), the simply significant differences were between the group of Geo.1, Geo.ii, EDFM, and Sela, Deep being in between.
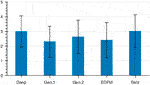
FIGURE 12. Average Likert ratings for the argument "They preserve the identity of the person". Deep and Sela are significantly dissimilar to Geo.1 and EDFM.
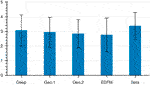
Effigy xiii. Average Likert ratings for the statement "I similar the results". Geo.i, Geo.2, and EDFM are significantly different to Sela.
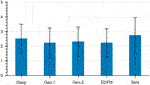
FIGURE 14. Average Likert ratings for the statement "They correspond to what would be expected of a extravaganza". Geo.1, Geo.ii, and EDFM are significantly dissimilar to Sela.
6 Discussion
In this paper, we have proposed two novel caricaturization methods. 1 leveraging the capabilities of deep fashion transfer networks for caricaturization (Deep), and the two remaining are variations of a gradient-based EDFM, with and without the employ of a information driven face shape stylization (Geo.ane and Geo.2).
The proposed methods, and ii additional methods from the literature were evaluated through a user study considering 12 different facial scans and the corresponding caricature generated from these different methods. Overall, the results showed that all methods achieved similar performances, average ratings going from 2.82 to 3.12 (lower is better). An ascertainment from the results is that in general, at that place was not a method which was significantly superior to the others. The results considering only the method (see Effigy 12) evidence a adequately distributed results, although Deep and Sela approaches seem to generate a higher number of "badly ranked caricatures" (fourth and fifth ranks). This observation matches with the global appreciation from participants, as EDFM, Geo.one and Geo.2 got slightly higher scores. While this upshot could suggest that some of the methods worked better from some facial scans than others, the results split by Identity practise not totally support this hypothesis (see Figure 11). Looking at the summit five worst ranked caricatures (Figure 15), we can identify several cases in which the method considered could have generated undesired results. The facial features of face six interpenetrate each other when using Sela, and the borders of face 7 are spread too widely using the same method. On face 5, heart size deviation is too profoundly exaggerated with the method Deep. These generated faces rated significantly worse than others on boilerplate tin can be easily identified, opening possibilities of a manual or automatic filtering protocol. Still, these results seem to evidence that some methods had a particularly bad operation on some of the facial scans. Withal, this did not happen consistently. Each caricaturization method had a pre-defined set of meta-parameters. The chosen configuration could have suited better some faces than others, generating caricatures of dissimilar qualities. The top 5 best ranked caricatures can be seen on Figure eight.
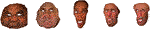
FIGURE xv. The five worst caricatures (with the worst mean ranks; identities 6, 7, 5, xi, 12).
Another potential caption for the results is that the task was besides hard and subjective, choices ending up being random. Using faces with no hair or eyes might have even increased the complexity of the task. Indeed, some participants explicitly stated that the task was difficult, particularly as they were judging textured facial masks instead of full faces. Nevertheless, this potential user preference does not seem to be linked with whatever particular caricaturization method. Looking at participant preferences, only 12 participants out of 49 showed a pregnant rating variation between methods ranked start. Looking at results on subjective questions, the 2 worse rated (Deep and Sela) methods rank-wise (beingness too those with the worst rated specific caricatures) were rated higher both at "They correspond to what would be expected of a caricature" and "I like the effect," where caricatures of each method were presented globally, suggesting that without their bad results on specific faces–which might exist less visible when presented amidst all the others–they could actually have ranked higher than other methods. The conception of a perceptual metric reliably judging the quality of a extravaganza could help guide its creation, simply the high variation of participant preferences in our report propose that information technology would require a considerably larger report to be defined.
Considering these findings, nosotros issue the following guidelines for choosing a method to generate caricatures automatically.
• If the master goal is to generate caricatures with a given set up of parameters, no specific mode, and as piddling variance as possible in quality, an EDFM-based method is the most suitable.
• If there is nevertheless no specific style required, but more tolerance to variance in quality (for instance if it is possible to tune the generated faces when they are unsatisfying), we recommend the approach of Sela, rated very similarly to EDFM on average in the rankings task, and significantly more on the subjective questionnaire.
• If a specific extravaganza style is required, the Deep arroyo will offering results comparable with Sela both in the ranking task and the questionnaire.
• Finally, if there is a need to target a specific user, the best solution is to use the panel of available methods, and leave the selection to them.
Caricatures provide a way whose notion can be understood equally an "accentuation of facial features," allowing manually divers rules to achieve comparable performance to learning-based approaches. Other stylistic facial domains, such as aliens or anthropomorphic animals could have more to gain from learning. Such non-realistic 3D facial data is although currently very scarce.
7 Conclusion
In this paper we have introduced two novel approaches to automatically generate caricatures from 3D facial scans. T he starting time method mixes EDFM-based curvature deformation and information driven proportion deformation, while the second method is based on a domain-to-domain translation deep neural network. Then, we present and talk over a perceptual written report aiming to assess the quality of the generated caricatures. Overall, the results showed that the different evaluated methods performed in a like way, although their performance could vary with respect to the facial scan used. This result illustrates both the subjectivity of evaluating caricaturization operation, forth with the complementarity of using dissimilar approaches, producing unlike styles of caricatures. Future piece of work could involve looking into automated detection of the worse cases of automatic caricaturization, to apply a correction or a filter, or exploring learned-based automated caricaturization by learning on different caricature styles, and setting up a network able to generate faces of a given style. We believe this study of the extended state of the art have helped grow and precise the landscape of automatic caricaturization approaches, and 3D facial stylization in general, and that our work provides interesting insights and guidelines for the automatic generation of caricatures that volition help practitioners and inspire future research.
Data Availability Statement
The raw information supporting the conclusion of this article will exist fabricated bachelor by the authors, without undue reservation.
Ethics Statement
Ethical review and approval was not required for the report on human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author Contributions
NO contributed to this work during his PhD, GK during his Principal. They were supervised by FA, QA, FD, PG, LH, and FM.
Conflict of Involvement
Authors NO, GK, QA, FD, and PG were employed past the visitor InterDigital.
The remaining authors declare that the research was conducted in the absence of whatsoever commercial or financial relationships that could be construed every bit a potential conflict of interest.
Publisher'due south Note
All claims expressed in this article are solely those of the authors and practise not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any production that may be evaluated in this article, or claim that may be made past its manufacturer, is not guaranteed or endorsed past the publisher.
Acknowledgments
We wish to thank all the reviewers for their comments, and the participants in our experiment. This project has received funding from the European union's Horizon 2020 research and innovation programme under grant agreement No 952 147. This projection has received funding from the Association Nationale de la Recherche et de la Technologie nether CIFRE agreement No 2018/1656.
Supplementary Textile
The Supplementary Material for this article tin be found online at: https://world wide web.frontiersin.org/articles/10.3389/frvir.2021.785104/full#supplementary-fabric
References
Akleman, E., Palmer, J., and Logan, R. (2000). Making Farthermost Caricatures with a New Interactive 2d Deformation Technique with Simplicial Complexes. Proc. Vis., 100–105.
Google Scholar
Arjovsky, M., Chintala, S., and Bottou, L. (2017). "Wasserstein Generative Adversarial Networks," in International Briefing on Machine Learning (ICML), 214–223. ArXiv: 1701.07875.
Google Scholar
Blanz, 5., and Vetter, T. (1999). A Morphable Model for the Synthesis of 3D Faces. ACM SIGGRAPH, 187–194. doi:10.1145/311535.311556
CrossRef Total Text | Google Scholar
Booth, J., Roussos, A., Zafeiriou, Due south., Ponniah, A., and Dunaway, D. (2016). "A 3D Morphable Model Learnt from 10,000 Faces," in IEEE/CVF Conference on Reckoner Vision and Blueprint Recognition (CVPR). doi:x.1109/cvpr.2016.598
CrossRef Total Text | Google Scholar
Brennan, S. Eastward. (1985). Extravaganza Generator: The Dynamic Exaggeration of Faces by Calculator. Leonardo eighteen, 170–178. doi:10.2307/1578048
CrossRef Full Text | Google Scholar
Cai, H., Guo, Y., Peng, Z., and Zhang, J. (2021). Landmark Detection and 3d Face Reconstruction for Caricature Using a Nonlinear Parametric Model. Graphical Models 115, 101103. doi:ten.1016/j.gmod.2021.101103
CrossRef Total Text | Google Scholar
Chen, H., Zheng, North.-N., Liang, L., Li, Y., Xu, Y.-Q., and Shum, H.-Y. (2002). PicToon. ACM Multimedia. doi:10.1145/641007.641040
CrossRef Full Text | Google Scholar
Chen, Y.-50., Liao, Due west.-H., and Chiang, P.-Y. (2006). "Generation of 3d Caricature by Fusing Extravaganza Images," in IEEE International Briefing on Systems, Human being and Cybernetics. doi:x.1109/icsmc.2006.384498
CrossRef Full Text | Google Scholar
Choi, Y., Choi, 1000., Kim, M., Ha, J.-Westward., Kim, S., and Choo, J. (2018). "StarGAN: Unified Generative Adversarial Networks for Multi-Domain Epitome-To-Image Translation," in IEEE/CVF Conference on Computer Vision and Pattern Recognition (Salt Lake City, Utah: CVPR), 8789–8797. doi:10.1109/CVPR.2018.00916
CrossRef Total Text | Google Scholar
Choi, Y., Uh, Y., Yoo, J., and Ha, J.-W. (2020). "StarGAN V2: Various Image Synthesis for Multiple Domains," in IEEE/CVF Briefing on Figurer Vision and Blueprint Recognition (Virtual Event (originally Seattle): CVPR), 8185–8194. doi:10.1109/CVPR42600.2020.00821
CrossRef Full Text | Google Scholar
Cimen, G., Bulbul, A., Ozguc, B., and Capin, T. (2012). Perceptual Caricaturization of 3d Models. Computer Inf. Sci., 201–207. doi:10.1007/978-one-4471-4594-3_21
CrossRef Total Text | Google Scholar
Clarke, 50., Min Chen, Thou., and Mora, B. (2011). Automated Generation of 3d Caricatures Based on Artistic Deformation Styles. IEEE Trans. Vis. Comput. Graphics 17, 808–821. doi:10.1109/tvcg.2010.76
PubMed Abstract | CrossRef Total Text | Google Scholar
Danieau, F., Gubins, I., Olivier, N., Dumas, O., Denis, B., Lopez, T., et al. (2019). "Automatic Generation and Stylization of 3D Facial Rigs," in IEEE Conference on Virtual Reality and 3D User Interfaces (Osaka, Japan: VR), 784–792. doi:10.1109/VR.2019.8798208
CrossRef Full Text | Google Scholar
Eigensatz, Grand., Sumner, R. Due west., and Pauly, M. (2008). Curvature-domain Shape Processing. Computer Graphics Forum 27, 241–250. doi:10.1111/j.1467-8659.2008.01121.x
CrossRef Total Text | Google Scholar
Fujiwara, T., Koshimizu, H., Fujimura, Yard., Fujita, M., Noguchi, Y., and Ishikawa, N. (2002). A Method for 3d Face up Modeling and Caricatured Figure Generation. IEEE Int. Conf. Multimedia Expo two, 137–140. doi:ten.1109/ICME.2002.1035531
CrossRef Full Text | Google Scholar
Gong, Southward., Chen, L., Bronstein, Yard., and Zafeiriou, South. (2019). "Spiralnet++: A Fast and Highly Efficient Mesh Convolution Operator," in IEEE/CVF International Conference on Computer Vision Workshop (Seoul, South Korea: ICCVW), 4141–4148. doi:x.1109/ICCVW.2019.00509
CrossRef Full Text | Google Scholar
Gooch, B., Reinhard, E., and Gooch, A. (2004). Man Facial Illustrations. ACM Trans. Graph. 23, 27–44. doi:ten.1145/966131.966133
CrossRef Full Text | Google Scholar
Goodfellow, I. J., Pouget-Abadie, J., Mirza, Thou., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). "Generative Adversarial Nets," in Conference on Neural Information Processing Systems (NIPS), 2672–2680. ArXiv: 1406.2661.
Google Scholar
Gu, Z., Dong, C., Huo, J., Li, W., and Gao, Y. (2021). Carime: Unpaired Extravaganza Generation with Multiple Exaggerations. IEEE Trans. Multimedia 1, one. doi:10.1109/TMM.2021.3086722
CrossRef Full Text | Google Scholar
Guo, Y., Jiang, L., Cai, L., and Zhang, J. (2019). 3D Magic Mirror: Automatic Video to 3D Caricature Translation. CoRR abs/1906, 00544. ArXiv: 1906.00544.
Google Scholar
Hong Chen, H., Ying-Qing Xu, Y.-Q., Heung-Yeung Shum, H.-Y., Song-Chun Zhu, Southward.-C., and Nan-Ning Zheng, North.-Due north. (2001). "Example-based Facial Sketch Generation with Non-parametric Sampling," in IEEE/CVF International Conference on Figurer Vision (ICCV). doi:10.1109/iccv.2001.937657
CrossRef Full Text | Google Scholar
Huang, 10., and Belongie, S. (2018a). "Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization," in IEEE/CVF International Conference on Estimator Vision (Munich, Deutschland: ICCV), 1510–1519. doi:10.1109/ICCV.2017.167
CrossRef Full Text | Google Scholar
Huang, X., Liu, M.-Y., Belongie, S., and Kautz, J. (2018b). "Multimodal Unsupervised Image-To-Image Translation," in Proceedings of the European Briefing on Figurer Vision (Newcastle, Uk: ECCV), 179179–196196. doi:10.1007/978-iii-030-01219-9_11
CrossRef Total Text | Google Scholar
Huo, J., Li, W., Shi, Y., Gao, Y., and Yin, H. (2018). "Webcaricature: a Benchmark for Extravaganza Recognition," in British Car Vision Conference. ArXiv: 1703.03230.
Google Scholar
Kim, T., Cha, 1000., Kim, H., Lee, J. K., and Kim, J. (2017). "Learning to Discover Cross-Domain Relations with Generative Adversarial Networks," in International Conference on Machine Learning (Sydney, NSW: ICML), 1857–1865. doi:10.5555/3305381.3305573
CrossRef Full Text | Google Scholar
Kingma, D. P., and Ba, J. (2015). "Adam: A Method for Stochastic Optimization," in International Conference on Learning Representations, (ICLR). ArXiv: 1412.6980.
Google Scholar
Lin Liang, L., Hong Chen, H., Ying-Qing Xu, Y.-Q., and Heung-Yeung Shum, H.-Y. (2002). "Example-based Caricature Generation with Exaggeration," in Pacific Briefing on Computer Graphics and Applications. doi:10.1109/pccga.2002.1167882
CrossRef Full Text | Google Scholar
Litany, O., Remez, T., Rodola, Due east., Bronstein, A., and Bronstein, Thousand. (2017). "Deep Functional Maps: Structured Prediction for Dumbo Shape Correspondence," in IEEE/CVF International Conference on Calculator Vision (ICCV). doi:10.1109/iccv.2017.603
CrossRef Full Text | Google Scholar
Liu, J., Chen, Y., Miao, C., Xie, J., Ling, C. X., Gao, X., et al. (2009). Semi-supervised Learning in Reconstructed Manifold Infinite for 3d Caricature Generation. Figurer Graphics Forum 28, 2104–2116. doi:ten.1111/j.1467-8659.2009.01418.x
CrossRef Total Text | Google Scholar
Liu, M.-Y., Breuel, T., and Kautz, J. (2017). "Unsupervised Image-To-Image Translation Networks," in Conference on Neural Information Processing Systems (Long Embankment, CA: NIPS), 700–708. doi:10.5555/3294771.3294838
CrossRef Total Text | Google Scholar
Liu, Grand.-Y., Huang, X., Mallya, A., Karras, T., Aila, T., Lehtinen, J., et al. (2019). "Few-shot Unsupervised Prototype-To-Image Translation," in IEEE/CVF International Conference on Computer Vision (ICCV), 10550–10559. doi:10.1109/ICCV.2019.01065
CrossRef Total Text | Google Scholar
Liu, S., Wang, J., Zhang, M., and Wang, Z. (2012). 3-dimensional Cartoon Facial Animation Based on Fine art Rules. Vis. Comput. 29, 1135–1149. doi:10.1007/s00371-012-0756-2
CrossRef Total Text | Google Scholar
Maron, H., Galun, M., Aigerman, Due north., Trope, M., Dym, North., Yumer, Due east., et al. (2017). Convolutional Neural Networks on Surfaces via Seamless Toric Covers. ACM Trans. Graph. 36, 1–10. doi:10.1145/3072959.3073616
CrossRef Full Text | Google Scholar
Mescheder, L. M., Nowozin, Southward., and Geiger, A. (2018). Which Training Methods for gans Do Actually Converge? Int. Conf. Machine Larn. (Icml) fourscore, 3478–3487. ArXiv: 1801.04406.
Google Scholar
Mo, Z., Lewis, J. P., and Neumann, U. (2004). Improved Automated Caricature by Characteristic Normalization and Exaggeration. ACM SIGGRAPH. doi:x.1145/1186223.1186294
CrossRef Total Text | Google Scholar
Moschoglou, South., Ploumpis, S., Nicolaou, M. A., Papaioannou, A., and Zafeiriou, Due south. (2020). 3dfacegan: Adversarial Nets for 3d Confront Representation, Generation, and Translation. Int. J. Comput. Vis. 128, 2534–2551. doi:10.1007/s11263-020-01329-8
CrossRef Total Text | Google Scholar
Olivier, North., Hoyet, L., Danieau, F., Argelaguet, F., Avril, Q., Lecuyer, A., et al. (2020). "The Impact of Stylization on Confront Recognition," in ACM Symposium on Applied Perception. doi:10.1145/3385955.3407930
CrossRef Total Text | Google Scholar
Pengfei Li, P., Yiqiang Chen, Y., Junfa Liu, J., and Guanhua Fu, Grand. (2008). "3d Extravaganza Generation by Manifold Learning," in IEEE International Briefing on Multimedia and Expo. doi:10.1109/icme.2008.4607591
CrossRef Full Text | Google Scholar
Ranjan, R., Sankaranarayanan, S., Castillo, C. D., and Chellappa, R. (2017). "An All-In-One Convolutional Neural Network for Face Assay," in IEEE International Conference on Automatic Face up and Gesture Recognition (FG), 17–24. doi:10.1109/FG.2017.137
CrossRef Total Text | Google Scholar
Sela, G., Aflalo, Y., and Kimmel, R. (2015). Computational Caricaturization of Surfaces. Computer Vis. Image Understanding 141, 1–17. doi:ten.1016/j.cviu.2015.05.013
CrossRef Full Text | Google Scholar
Shi, Y., Deb, D., and Jain, A. K. (2019). "WarpGAN: Automatic Caricature Generation," in IEEE/CVF Conference on Computer Vision and Design Recognition (CVPR). doi:10.1109/cvpr.2019.01102
CrossRef Full Text | Google Scholar
Taigman, Y., Polyak, A., and Wolf, L. (2017). "Unsupervised Cross-Domain Epitome Generation," in International Conference on Learning Representations (ICLR). ArXiv: 1611.02200.
Google Scholar
Wang, C., Chai, M., He, M., Chen, D., and Liao, J. (2021). "Cross-Domain and Disentangled Face Manipulation with 3D Guidance," in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). ArXiv: 2104.11228.
Google Scholar
Wu, Q., Zhang, J., Lai, Y.-K., Zheng, J., and Cai, J. (2018). "Alive Caricature from 2d to 3d," in IEEE/CVF Briefing on Computer Vision and Design Recognition (CVPR). doi:10.1109/cvpr.2018.00766
CrossRef Total Text | Google Scholar
Xie, J., Chen, Y., Liu, J., Miao, C., and Gao, X. (2009). Interactive 3d Extravaganza Generation Based on Double Sampling. ACM Multimedia. doi:10.1145/1631272.1631403
CrossRef Full Text | Google Scholar
Ye, Z., Yi, R., Yu, Thou., Zhang, J., Lai, Y., and Liu, Y. (2020). "3d-carigan: An Stop-To-Terminate Solution to 3d Caricature Generation from Face Photos," in Computing Enquiry Repository (CoRR). ArXiv: 2003.06841.
Google Scholar
Yi, Z., Zhang, H., Tan, P., and Gong, Thou. (2017). "DualGAN: Unsupervised Dual Learning for Epitome-To-Image Translation," in IEEE/CVF International Briefing on Computer Vision (ICCV). doi:10.1109/iccv.2017.310
CrossRef Full Text | Google Scholar
Zell, East., Aliaga, C., Jarabo, A., Zibrek, K., Gutierrez, D., McDonnell, R., et al. (2015). To Stylize or Not to Stylize? ACM Trans. Graph. 34, one–12. doi:x.1145/2816795.2818126
CrossRef Total Text | Google Scholar
Zhou, J., Tong, X., Liu, Z., and Guo, B. (2016). 3d Drawing Face Generation by Local Deformation Mapping. Vis. Comput. 32, 717–727. doi:x.1007/s00371-016-1265-5
CrossRef Full Text | Google Scholar
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A. (2017). "Unpaired Epitome-To-Image Translation Using Bicycle-Consistent Adversarial Networks," in IEEE/CVF International Conference on Estimator Vision (ICCV). doi:10.1109/ICCV.2017.244
CrossRef Total Text | Google Scholar
Source: https://www.frontiersin.org/articles/10.3389/frvir.2021.785104/full?msclkid=0b23db1fb8e711ec8d2d9586d0c363ac
0 Response to "Planes of a Human Face Used to Draw Caricatures"
ارسال یک نظر